5 najczęstszych błędów SEO w Robots.txt


Plik robots.txt to mały i prosty plik tekstowy umieszczony na serwerze naszej strony internetowej, który jednak ma potężny wpływ na to w jaki sposób roboty wyszukiwarek postrzegają naszą witrynę. Podejmując pracę nad jakąkolwiek stroną internetową, jedną z pierwszych rzeczy jaką sprawdzam jest właśnie zawartość pliku robots.txt
1. Brak pliku robots.txt
Brak pliku robots.txt to niestety częsty błąd na wielu stronach internetowych. Co prawda w takiej sytuacji roboty uznają, że mogą przeglądać całą zawartość witryny do jakiej dotrą, ale dobrą praktyką jest posiadanie choćby domyślnego pliku robots.txt o przykładowej zawartości:
User-agent: *
Disallow:
Dlaczego? Powodów jest kilka. Każdy szanujący się robot w pierwszej kolejności pyta o plik robots.txt, a jeżeli go nie znajduje to dostaje naszą stronę w komunikatem „404 nie znaleziono”. Powoduje to niepotrzebny transfer i generuje logi błędów w statystykach.
Drugi powód to tylko moja niepotwierdzona teoria – brak pliku robots.txt może być negatywnym czynnikiem rankigowym w SEO (jednym z bardzo wielu różnych). Świadczy o niedbałości strony. Wiele strona zapleczowych nie ma pliku robots.txt
Jak sprawdzić czy mam i jak wygląda mój plik robots.txt? Wystarczy wpisać w przeglądarce jego adres w Twoim serwisie, przykładowo https://redseo.pl/robots.txt
2. Blokowanie ważnych stron w serwisie
Problem wydaje się banalny, ale występuje częściej niż można przypuszczać. Nieumyślne zablokowanie ważnych stron lub całego serwisu w robots.txt – nie trzeba być geniuszem aby domyślić się iż może spowodować to drastyczne spadki pozycji w wynikach wyszukiwarki.
Taki problem często pojawia się przy wdrażaniu nowej strony lub jej przebudowy. Webmaster skopiował robots.txt z wersji testowej, który wszystko blokował – częsty problem. Zdarzają się też literówki w składni, lub dodanie reguły, która blokuje to co chcemy ale może też blokować inne rzeczy z których nie zdajemy sobie sprawy.
Pomocne jest tu narzędzie „Tester pliku robots.txt” dostępne w Narzędziach Google dla Webmasterów. Umożliwia sprawdzenie konkretnego adresu URL w naszej witrynie pod względem dyrektyw jakie znajdują się w pliku robots.txt. Jest to szczególnie przydatne dla dużych plików robots.txt zawierających wiele dyrektyw w których łatwo się pogubić:
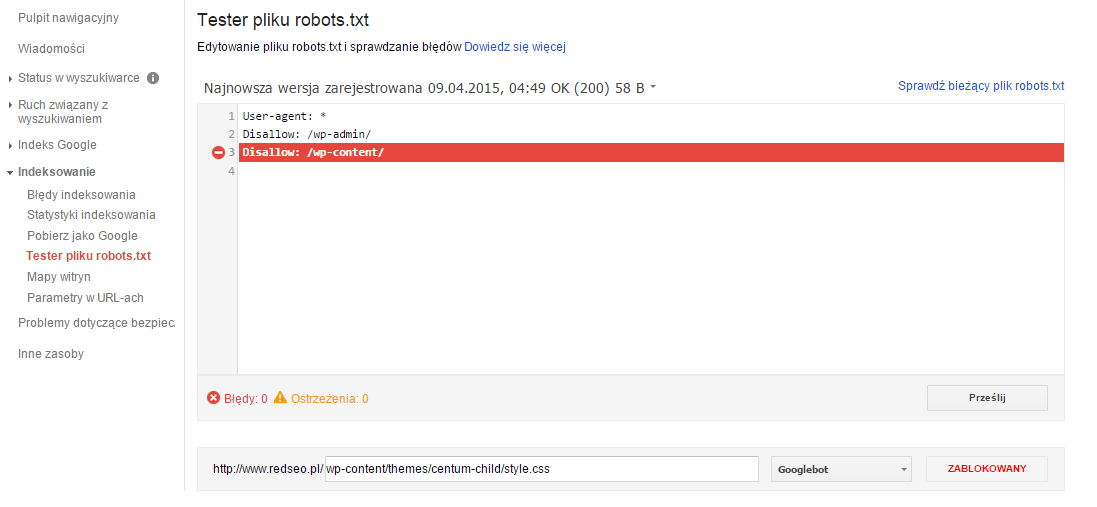
3. Blokowanie obrazków i plików CSS/JS
Problem spotykany na bardzo wielu stronach internetowych. Dyrektywy zawarte w pliku robots.txt blokują robotom dostęp do obrazków lub plików CSS odpowiedzialnych z wygląd oraz skryptów JavaScript. W rezultacie robot wyszukiwarki widzi Twoją stronę tak:
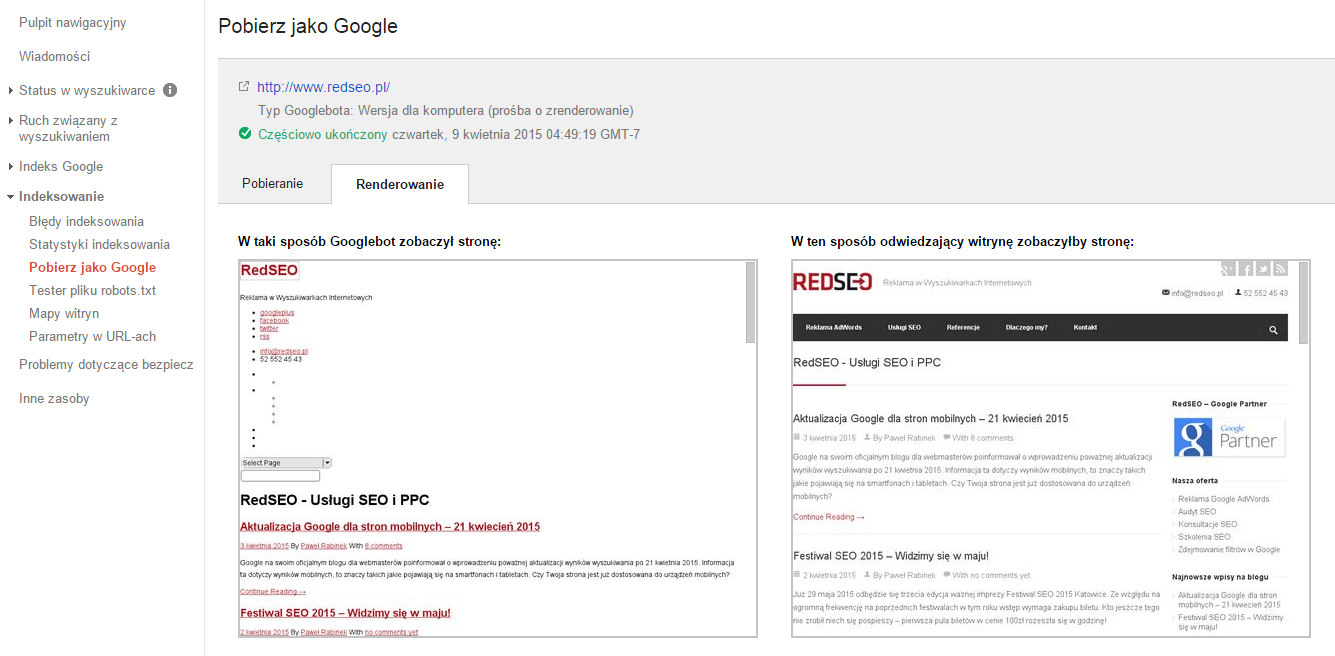
Nie wygląda to najlepiej. Koniecznie należy umożliwić dostęp do tego typu zasobów. Ma to wpływ na SEO, może mieć także wpływ na ocenę jakości strony docelowej przez system AdWords. Pomocne w rozwiązaniu tego problemu są Narzędzia Google dla Webmasterów gdzie dostępny jest moduł „Pobierz jako Google„. Dzięki temu narzędziu szybko sprawdzimy jak widzi stronę robot Google oraz jakie zasoby są blokowane.
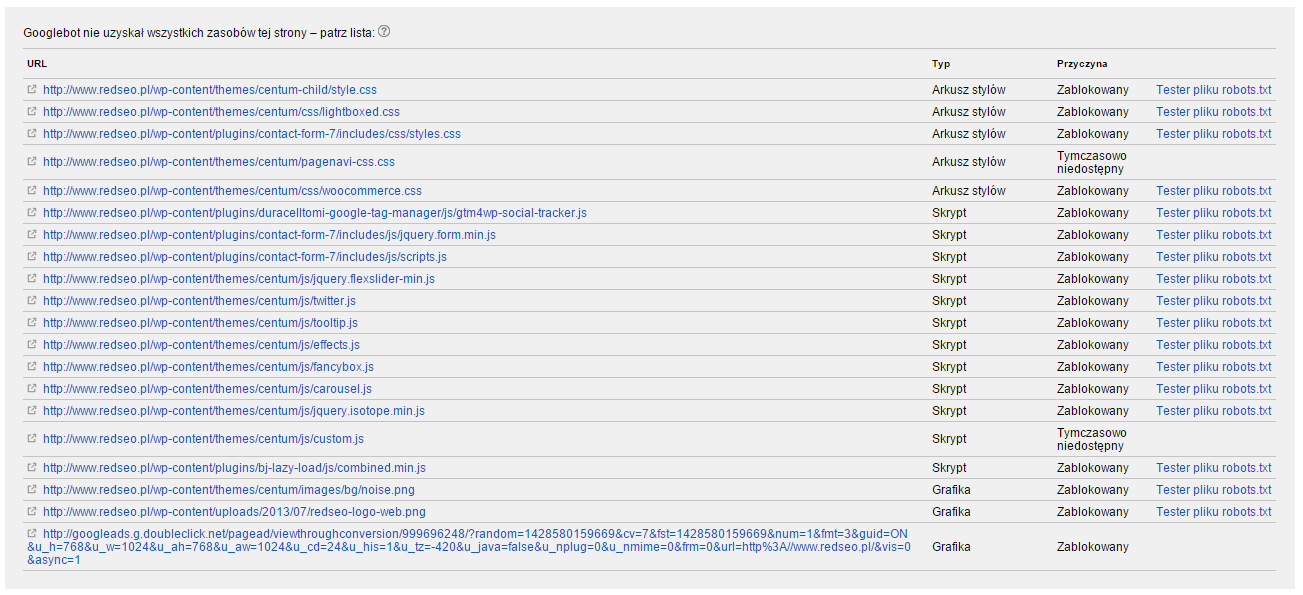
Ważne jest aby doprowadzić do sytuacji w której robot wyszukiwarki i użytkownik widział taką samą stronę internetową:
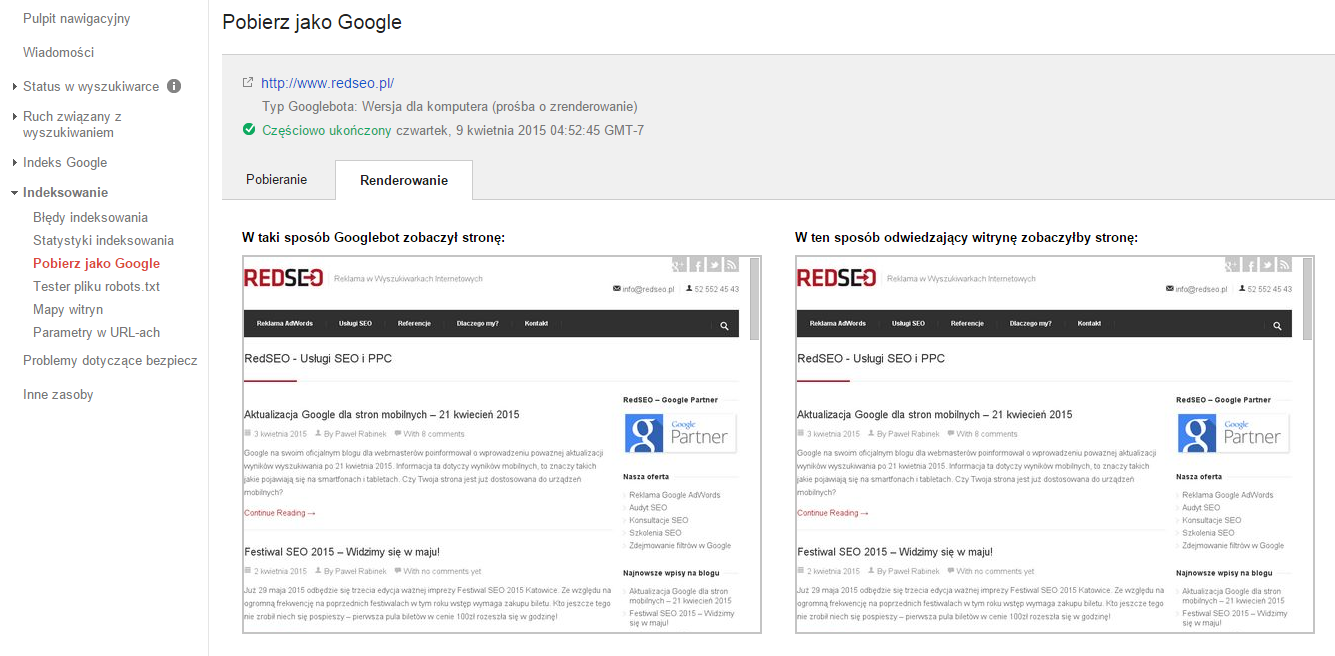
4. Blokowanie robota to nie usuwanie z indeksu!
Rzecz o której często się zapomina. Blokada dostępu w pliku robots.txt to nie jest to samo co usunięcie strony z indeksy wyszukiwarki Google! Jeżeli chcemy usunąć jakąś stronę z wyników wyszukiwania należy skorzystać z meta tagu „robots” ustawionego na „noindex„. Trzeba też pamiętać, że jednoczesne ustawienie blokady w robots.txt i meta tagu, sprawi, że robot nie pozna wartości meta tagu – będzie blokowany przez robots.txt…
Poniżej przykład blokady w robots.txt która jednak nie usuwa stron z indeksu wyszukiwarki Google:
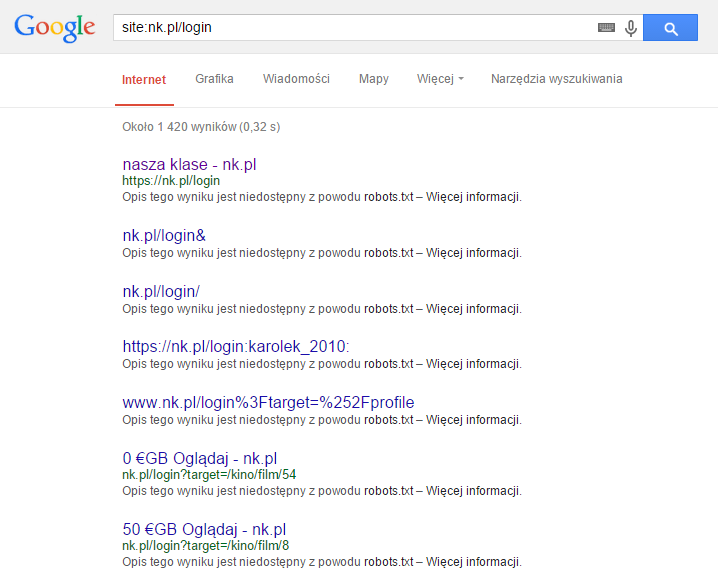
5. Utrata „link juice”
Link juice czyli linkowy soczek – moc linków prowadzących do Twojego serwisu oraz linków wewnętrznych. Może się zdarzyć, że strona w serwisie która jest blokowana dla robotów posiada linki zewnętrzne pochodzące z zewnętrznych serwisów. W rezultacie moc linków przychodzących nie jest ani wykorzystywana przez tą podstronę, ani nie jest dalej dystrybuowana na kolejne podstrony podlinkowane z zablokowanej zawartości.
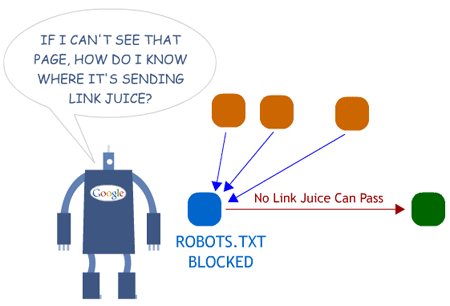
Źródło moz.com/learn/seo/robotstxt
Warto więc co jakiś czas wykonać audyt linków przychodzących i sprawdzić czy istnieją linki kierujące do treści zablokowanych przez robots.txt. Jeżeli tak, warto podjąć jakieś działania aby skutecznie wykorzystać te linki.
6. Bonus – Blokowanie złych robotów
O ile robots.txt służy do informowania robotów gdzie mogą i gdzie nie mogą wchodzić, o tyle złośliwe roboty kompletnie to ignorują. Oczywiście można w robots.txt zablokować złośliwe spamboty, które zjadają transfer i obciążają serwer, ale może być to nieskuteczne. O wiele skuteczniejszą metodą jest zablokowanie ich na poziomie serwera lub w pliku .htaccess.
Podsumowując. Sprawdź co siedzi w Twoim pliku robots.txt. Korzystając z Narzędzi Google upewnij się czy Twoja strona jest dobrze „widziana” przez robota. Jeżeli masz dodatkowe pytania o konfigurację lub problemy z robots.txt napisz do mnie.
